高性能网络之DPDK与RDMA浅析
高性能网络之DPDK与RDMA浅析
DPDK(Data Plane Development Kit)
1. 定义
DPDK 是一个 用户空间高速数据包处理框架,由 Intel 发起并开源,旨在绕过内核协议栈,实现高性能、低延迟的数据包处理。
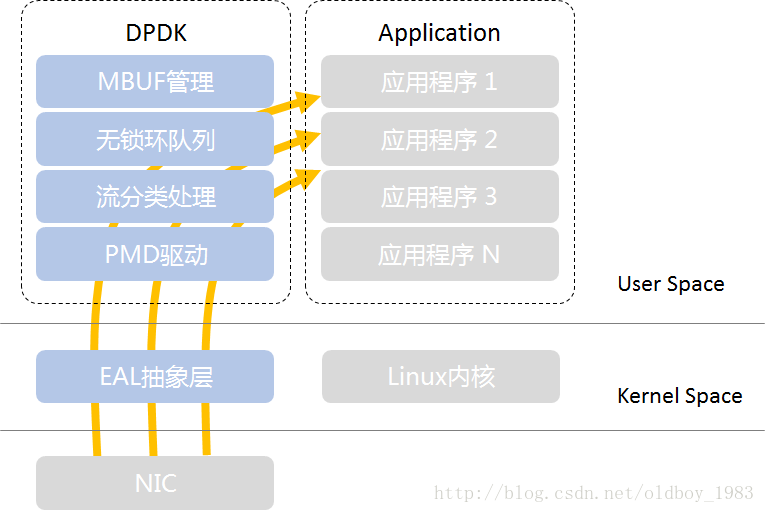
- PMD:Pool Mode Driver,轮询模式驱动,通过非中断,以及数据帧进出应用缓冲区内存的零拷贝机制,提高发送/接受数据帧的效率
- 流分类:Flow Classification,为N元组匹配和LPM(最长前缀匹配)提供优化的查找算法
- 环队列:Ring Queue,针对单个或多个数据包生产者、单个数据包消费者的出入队列提供无锁机制,有效减少系统开销
- MBUF缓冲区管理:分配内存创建缓冲区,并通过建立MBUF对象,封装实际数据帧,供应用程序使用
- EAL:Environment Abstract Layer,环境抽象(适配)层,PMD初始化、CPU内核和DPDK线程配置/绑定、设置HugePage大页内存等系统初始化
2. 核心原理
- 绕过内核协议栈:数据包从网卡直接进入用户空间,避免内核上下文切换和中断开销。
- 轮询模式:通过轮询而非中断方式处理数据包,减少延迟。
- 大页内存(Hugepages):使用大页内存提升内存访问效率。
- 多核并行处理:支持多线程并行处理数据包,充分利用多核 CPU 资源。
3. 关键特性
| 特性 | 描述 |
|---|---|
| 零拷贝 | 数据包在用户空间直接处理,无需复制到内核 |
| 无中断 | 使用轮询模式,减少中断开销 |
| 多核优化 | 支持线程绑定到特定 CPU 核心 |
| 硬件加速 | 支持 Intel、Mellanox、Broadcom 等厂商的网卡驱动 |
| 协议栈轻量化 | 可选精简协议栈或完全自定义 |
4. 应用场景
- 网络功能虚拟化(NFV):如虚拟交换机、虚拟路由器
- 5G 基站通信:高吞吐量、低延迟要求
- 金融高频交易:微秒级延迟要求
- DDoS 防护系统:高吞吐包处理
- 网络监控工具:实时流量分析
5. 优缺点
| 优点 | 缺点 |
|---|---|
| 高性能(10Gbps~100Gbps) | 开发复杂度高 |
| 低延迟(微秒级) | 需要专用驱动和硬件支持 |
| 支持多核并行处理 | 内存占用大(依赖大页) |
| 可扩展性强 | 不兼容标准 socket API |
RDMA(Remote Direct Memory Access)
1. 定义
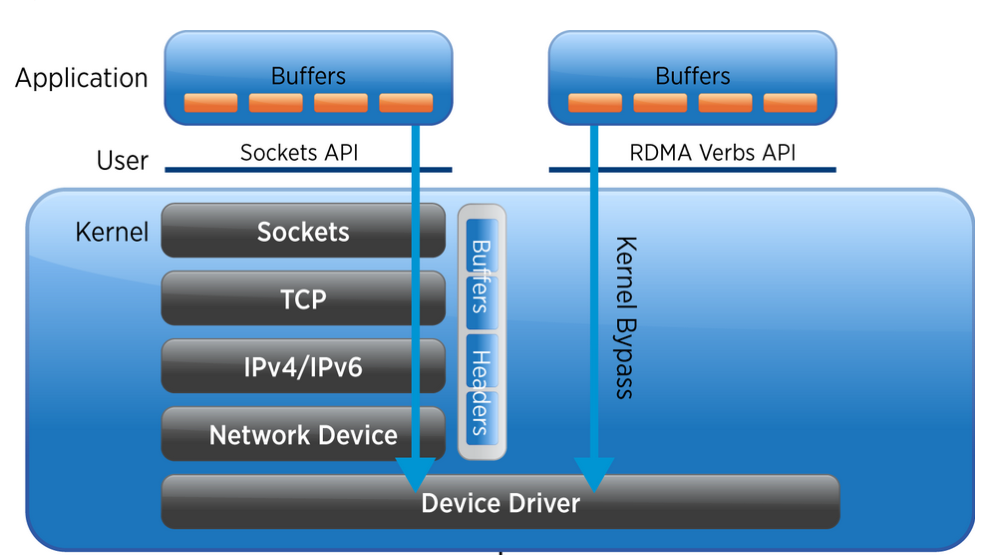
RDMA 是一种 远程直接内存访问技术,允许在 不经过 CPU 和操作系统 的情况下,直接读写远程主机内存。其目标是实现 零拷贝、零中断、低延迟 的数据传输。
2. 核心原理
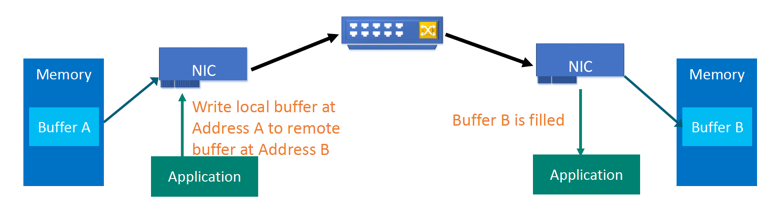
- 绕过 CPU:数据直接从网卡写入/读取远程主机内存。
- 零拷贝:无需内核与用户空间复制。
- 零中断:数据传输过程中不触发 CPU 中断。
- 硬件卸载:依赖特定硬件(如 InfiniBand、RoCE、iWARP)完成数据传输。
3. 关键技术
| 技术 | 描述 |
|---|---|
| InfiniBand | 高速互联协议,原生支持 RDMA |
| RoCE(RDMA over Converged Ethernet) | 在以太网上实现 RDMA |
| iWARP | 在 TCP/IP 协议栈中实现 RDMA |
| UMR(User-mode RDMA) | 用户态直接操作 RDMA 设备 |
| Memory Registration | 注册内存区域供远程访问 |
4. 应用场景
- 高性能计算(HPC):如超算集群通信
- 分布式存储(如 Ceph、分布式数据库)
- 云计算虚拟机迁移
- AI/ML 训练集群通信
- 金融实时交易系统
5. 优缺点
| 优点 | 缺点 |
|---|---|
| 极低延迟(亚微秒) | 硬件依赖性强(如 Mellanox、Intel) |
| 零拷贝、零中断 | 配置和维护复杂 |
| 高带宽(可达 100Gbps~400Gbps) | 不兼容传统 TCP/IP 协议栈 |
| 节省 CPU 开销 | 网络需支持 RoCE 或 InfiniBand |
📊 DPDK vs RDMA 对比表
| 对比项 | DPDK | RDMA |
|---|---|---|
| 目标 | 高性能数据包处理 | 高性能内存访问 |
| 是否绕过内核 | 是(用户空间) | 是(硬件直接访问) |
| 是否需要 CPU 参与 | 需要(用户态处理) | 不需要(硬件完成) |
| 是否需要特殊硬件 | 是(支持 DPDK 的网卡) | 是(支持 RDMA 的网卡) |
| 是否零拷贝 | 是(用户空间处理) | 是(硬件直连内存) |
| 是否零中断 | 是(轮询模式) | 是(硬件完成传输) |
| 是否支持标准协议栈 | 否(需自定义协议栈) | 否(依赖底层传输协议) |
| 典型延迟 | 微秒级(μs) | 亚微秒级(<1μs) |
| 典型带宽 | 10Gbps~100Gbps | 100Gbps~400Gbps |
| 开发难度 | 高(需编写用户态协议栈) | 极高(需理解硬件寄存器) |
| 适用网络类型 | 以太网 | InfiniBand、RoCE、iWARP |
DPDK 与 RDMA 的结合使用
在某些高性能场景中,DPDK 和 RDMA 可以结合使用:
场景:高性能分布式存储系统
- DPDK:用于本地数据包处理(如接收客户端请求)
- RDMA:用于节点间数据传输(如副本同步、缓存读写)
优势:
- DPDK 提供灵活的数据包处理能力
- RDMA 提供高速数据传输能力
挑战:
- 开发复杂度极高
- 硬件依赖性强
- 调试困难
如何选择 DPDK 还是 RDMA?
按技术需求选择
| 选择依据 | DPDK 更适合 | RDMA 更适合 |
|---|---|---|
| 是否需要定制协议栈 | ✅ 需要 | ❌ 不需要 |
| 是否需要零拷贝 | ✅ 是 | ✅ 是 |
| 是否需要零中断 | ✅ 是 | ✅ 是 |
| 是否依赖硬件加速 | ✅ 是 | ✅ 是 |
| 是否需要跨网络通信 | ✅ 是 | ✅ 是 |
| 是否需要低延迟 | ✅ 微秒级 | ✅ 亚微秒级 |
| 是否需要高带宽 | ✅ 可达 100Gbps | ✅ 可达 400Gbps |
| 是否需要开发协议栈 | ✅ 需要 | ❌ 不需要(依赖底层) |
| 是否支持 TCP/IP 协议 | ❌ 不支持 | ❌ 不支持 |
| 是否适合云原生环境 | ✅ 适合 | ❌ 不适合(需特殊网络) |
按场景需求选择
| 场景 | 技术选择 | 理由 |
|---|---|---|
| 需要灵活协议栈 | ✅ DPDK | 可自定义包处理逻辑 |
| 需要极低延迟和高带宽 | ✅ RDMA | 无需 CPU 参与 |
| 数据中心内部通信 | ✅ RDMA | 支持高速内存访问 |
| 需要支持 TCP/IP 或 GTP-U | ✅ DPDK | 需要自定义协议栈 |
| 需要多租户隔离和虚拟化支持 | ✅ DPDK | 支持 SR-IOV 和虚拟化 |
| 需要跨网络通信 | ✅ DPDK | 无需特殊网络支持 |
| AI/ML 集群通信 | ✅ RDMA | 支持 GPU 直接访问内存 |
| 云原生网络加速 | ✅ DPDK | 支持容器化部署 |
| 金融高频交易 | ✅ RDMA | 极低延迟 |
| 网络监控/安全设备 | ✅ DPDK | 需要灵活处理数据流 |
总结
DPDK和RDMA:
相同点:
- 两者均为kernel bypass技术,可以减少中断次数,消除内核态到用户态的内存拷贝;
相异点:
- DPDK是将协议栈上移到用户态,而RDMA是将协议栈下沉到网卡硬件,DPDK仍然会消耗CPU资源;
- DPDK的并发度取决于CPU核数,而RDMA的收包速率完全取决于网卡的硬件转发能力
- DPDK在低负荷场景下会造成CPU的无谓空转,RDMA不存在此问题
- DPDK用户可获得协议栈的控制权,可自主定制协议栈;RDMA则无法定制协议栈
📚 相关资料
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 DD'Notes!
 微信
微信 支付宝
支付宝

评论